 410人浏览过
410人浏览过摘要:分布式计算的思想是将一个大任务分割成多个小任务同时执行,降低任务执行时间。这样看来,似乎任务分割得越小越好——这样每个任务都能很快完成,其实不然,给定计算资源,同时能够处理的任务数量是固定的

分布式计算的思想是将一个大任务分割成多个小任务同时执行,降低任务执行时间。这样看来,似乎任务分割得越小越好——这样每个任务都能很快完成,其实不然,给定计算资源,同时能够处理的任务数量是固定的,且每个任务的启动都有开销,如果单个任务小,任务数量就多,计算集群需要分几轮来处理任务,同时花很多时间用于启动任务,效率不高。所以,要提高分布式计算的性能,并不是任务越小越好,而是要在任务大小和任务数量之间找到一个平衡点,最大化利用有限的计算资源。上期技术分享中,我们对Inceptor Holodesk进行了整体的介绍。这期我们将介绍Holodesk优化案例系列的第一例:分布式计算中的碎片自动合并(以下简称automerge),利用Holodesk的功能特性来找到这个平衡点并进行优化。在我们将要介绍的案例中,运行同一条SQL,使用Holodesk表相较使用TXT表性能提升了10倍,而在Holodesk表的基础上再使用automerge,相较TXT表性能则提升了30倍。
原理介绍
Holodesk以最大容量为256M的文件为单位保存数据,该文件单位称为block。执行SQL语句时,服务器在默认情况下为每个block分别开启一个对应的处理线程。一般情况下这样是合理的,但是如果总数据量比较大,或者小文件过多时,引擎的执行效率就会下降。在不改变数据分布的情况下,Inceptor提供了执行时自动合并小文件(下面简称automerge)的功能来提升效率。
使用方法
Automerge可以直接在Inceptor命令行中开启:

“ngmr.partition.automerge = true”表示开启automerge,它提供两种合并的方法:
1. “ngmr.partition.mergesize = n”表示将n个block安排给单个任务来处理。
2. “ngmr.partition.mergesize.mb=m”,表示一个task负责处理大小为m的数据量(单位为MB)。
用户可以根据需要仅设置这两个参数其中之一,默认使用方法2来控制,如果需要使用方法1,需要将mergesize.mb设为-1。
在block中数据量偏少的情况下,单个任务运行的时间就少,那么任务开启的开销很可能占据总开销的大量比例。尤其当小文件数量过于庞大时,过多的线程将导致排队延时的增加。所以对block有效的合并处理有助于促进语句执行的高效性。
如果已知数据源中小文件过多,用户向新表中导入数据前可以打开automerge开关,使一个Task处理多个block,并将结果输出到同一个文件中,因此达到了小文件合并效果。数据导入完成后用户便可关闭automerge开关,今后不用再对该表开启automerge。
除了检查block的大小,还可以通过TDH的管理界面查看任务第一阶段Task的数量和每个Task的运行时间判断是否需要automerge。第一阶段Task负责Map端任务,如果第一阶段Task过多而且每个Task执行时间短,表示小block过多,从而整体任务运行效率低,此时需要启用automerge。注意,不建议为每个线程处理过多的block。我们在调整相关参数时,在下限的时候,尽量保证单个Task的处理时间不要低于2s,在调整上限的时候,要注意对应的Task的GC时间占总执行时间的比例不要超过20%。
优化案例
下面,我们以一则实际的应用证实以上提及的优化方法是可以在适当的时候起到显著作用的。我们将在以下情况下对TPC-DS中的store_sales表(有十四亿条左右的记录)进行count(*):
1. store_sales表为TXT表;
2. store_sales表为Holodesk表;
3. store_sales表为Holodesk表并使用automerge优化;
我们将执行的SQL为:

1.当store_sales表为TXT表:
通过管理界面(如Figure 1所示),我们看到对TXT格式的store_sales表的执行分为了两个阶段,总共所花时间约为90秒。
 Figure 1 store_sales为TXT表时count(*)的执行时间
Figure 1 store_sales为TXT表时count(*)的执行时间
2.当store_sales表为Holodesk表:
创建一张没有经过任何优化处理的Holodesk表store_sales。如Figure 2所示:
 Figure2 store_sales的block数和大小
Figure2 store_sales的block数和大小
数据量共有121.9G,所有数据分给了1500个block存储。每个block的大小如Figure 3所示,大约在60-70M之间。
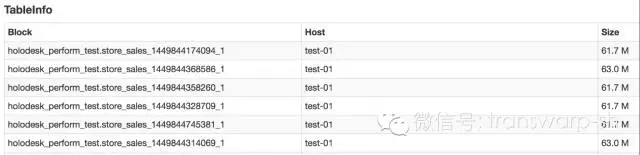 Figure3 store_sales其中六个block的信息
Figure3 store_sales其中六个block的信息
现在,在不做任何优化的情况下对store_sales执行一次count(*)。首先在管理界面可以看到(如Figure 4所示),这条语句分为了两个阶段,总共执行了约9.0s。因为第一阶段是为每个block开启一个对应线程,所以共有1500个Tasks。我们看到在没进行任何优化的情况下,使用Holodesk表的查询速度已经是使用TXT表的10倍。
 Figure4 优化前count(*)执行的两个阶段的信息
Figure4 优化前count(*)执行的两个阶段的信息
Figure5截取了其中六个线程的信息,每个线程的数据读取量大约为135.0B。
 Figure 5 优化前count(*)的Map阶段其中六个线程的部分信息
Figure 5 优化前count(*)的Map阶段其中六个线程的部分信息
3.对Holodesk表store_sales使用automerge优化
在前面的Figure 3中我们看到该表的每个block大小在60-70M,而最优情况应该为每个线程安排200M的处理量,所以我们打开automerge,并将任务并发处理量设置为3。做这样的处理后,如Figure 6所示,总的运行时间降到3.0s,其中Map阶段变化明显,由7.0s减为1.0*ap 端的线程数量缩减为301个。在使用Holodesk的基础上使用automerge优化,运行速度进一步提高,达到了TXT表的30倍。
 Figure 6 启用automerge后count(*)执行的两个阶段的信息
Figure 6 启用automerge后count(*)执行的两个阶段的信息
另外由Figure 7所示,每个线程的数据读取量增加到684.0B左右。这些证明了每个线程确实负责处理多个block的数据,打开automerge开关的确能够缩短运行时间。
 Figure7 启用automerge后count(*)执行时Map端的其中六个线程的部分信息
Figure7 启用automerge后count(*)执行时Map端的其中六个线程的部分信息
总结
Automerge是Holodesk最基础的优化方法。通过对SQL执行的简单分析,我们已经能是查询速度大大提升。下期我们将介绍在运行复杂SQL时,如何使用CUBE优化,使Holodesk表查询性能打到TXT表的百倍以上。欢迎继续关注我们的技术分享。
 0
0 举报
举报
 登录后可评论
登录后可评论



.jpg)



.jpg)


